
Optimizing Distributed Training of Language Models: A Dive into DiLoCo and Practical Optimizer Implementations

Introduction:
The advent of large language models (LLMs) has revolutionized various aspects of machine learning, but training these behemoths remains a formidable challenge, especially in distributed environments. This article delves into DiLoCo (Distributed Low-Communication), a novel training method developed by Arthur Douillard and colleagues at Google DeepMind, designed specifically for these scenarios. Additionally, we explore practical implementations of different optimizers in PyTorch, demonstrating their impact on neural network training.
Deep Dive into DiLoCo:
DiLoCo tackles the challenges of training LLMs across distributed systems where resources are dispersed and connectivity is limited. It significantly reduces the need for frequent communication between computational nodes, a common bottleneck in traditional training methods. This approach not only enhances efficiency but also maintains, and in some cases, improves model performance.
Technical Implementation of DiLoCo:
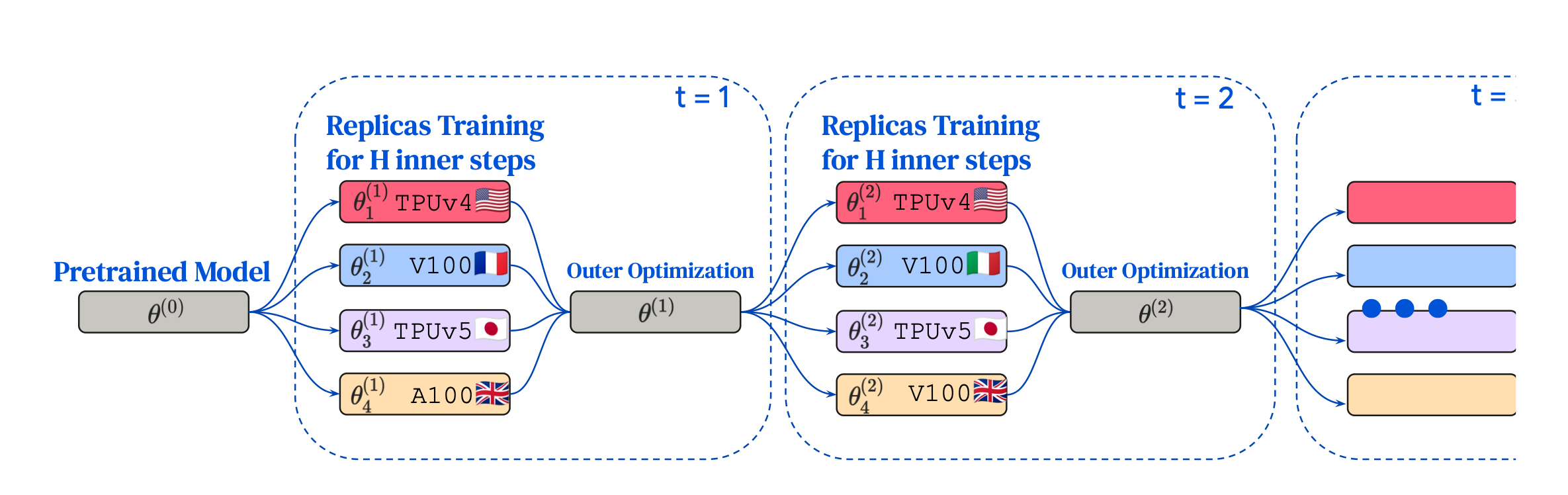
At the heart of DiLoCo's strategy are two distinct optimization processes:
Inner Optimization: Utilizing AdamW, each distributed node independently updates its local model based on its data shard. This phase requires minimal inter-node communication.
Outer Optimization: Leveraging Nesterov Momentum, DiLoCo aggregates updates from all nodes, applying them to the global model. This step is crucial in environments with infrequent communication.
Comparison with Traditional Methods:
DiLoCo's methodology stands in contrast to Federated Averaging (FedAvg) and the Adam optimizer. While FedAvg involves higher communication overhead and typically relies on SGD, DiLoCo's reduced communication strategy and sophisticated optimizer choice (Nesterov Momentum) set it apart. The Adam optimizer, known for its adaptability, is used in DiLoCo's inner optimization phase, showcasing its versatility.
Practical Implementation of Optimizers in PyTorch:
To further understand these concepts, let's turn to PyTorch, a leading machine learning framework. Here's how different optimizers can be implemented:
Defining a Simple Neural Network:
class SimpleNet(nn.Module):
...
model = SimpleNet()Implementing Momentum and Nesterov Momentum:
optimizer_momentum = optim.SGD(model.parameters(), ...) optimizer_nesterov = optim.SGD(model.parameters(), ..., nesterov=True)Using the Adam Optimizer:
optimizer_adam = optim.Adam(model.parameters(), ...)Sample Training Loop:
for epoch in range(5):
for data, target in dataset:
...Conclusion:
DiLoCo presents a significant advancement in the distributed training of large language models, efficiently addressing the challenges posed by limited communication bandwidth. Its strategic use of AdamW and Nesterov Momentum optimizers exemplifies the innovative approaches needed to tackle modern machine learning problems. Understanding and implementing these techniques in frameworks like PyTorch not only broadens our toolkit but also deepens our comprehension of effective model training in distributed environments.
References:
https://arxiv.org/pdf/2311.08105.pdf